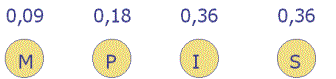| 29.2 Huffman - Algorithmus und Kompression | |
| Prinzip der Kompression | Die Idee
der Komprimierung basiert auf der Tatsache, dass die Zeichen eines Textes
in unterschiedlichen
Häufigkeiten auftreten. Dies wird schon sehr
deutlich bei dem Wort "MISSISSIPPI". Die relativen Häufigkeiten der
einzelnen Buchstaben sind:
H(M)= 0.09 Nun weicht man von der üblichen Kodierung der Zeichen ab. Solche, die häufiger vorkommen, bekommen einen Kode, der im Speicher weniger Platz belegen als Zeichen, die weniger häufig vorkommen. In folgendem Kode sind diese Forderungen erfüllt. Code(M) = 100 Die Zeichenkette "MISSISSIPPI" lässt sich dann wesentlich kürzer codieren: Code(MISSISSIPPI) = 100110011001110110111 die unterschiedliche Färbung zeigt, zu welchen Buchstaben sie gehören, genauer, jedes mal wenn sich die Farbe ändert, beginnt ein neues Zeichen. Durch Abzählen findet man, dass die Datenmenge der Zeichenkette jetzt nur noch 21 bit hat, eine Kompression auf ca. 23,9% der ursprünglichen Datenmenge.
Die Antworten auf diese drei Fragen findet wir im Huffman-Algorithmus, der an unserem Beispiel "MISSISSIPPI" aufgezeigt wird
|
| Huffman - Algorithmus |
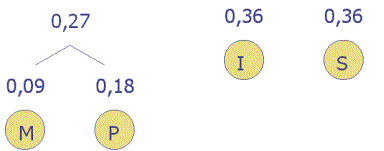
 Im ersten Schritt werden die Zeichen sortiert nach der rel. Häufigkeiten ihres Auftretens im zu komprimierenden Text aufgeschrieben:
Man sucht sich die zwei Häufigkeiten heraus, die die kleinste Summe bilden, das wären 0,09 + 0,18 = 0,27. Es ist dies immer die Summe der ersten beiden Glieder. Die Summe ersetzt die beiden Summanden samt ihren Zeichen, die unter die 0,27 gestellt werden. Diese Summe wird dann wieder in die Reihe so eingeordnet, dass die Sortierung nach der Häufigkeit erhalten bleibt.
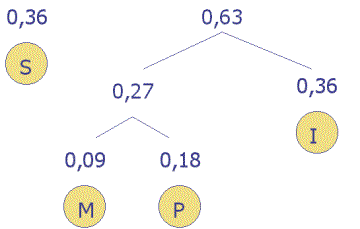
Der zweite Schritt des Algorithmus wird nun wiederholt: Die Summanden, die jetzt die kleinste Summe bilden, sind 0,27 und 0,36, ihre Summe ist 0,63. Ihre Zusammenfassung und ergibt nach dem Neuordnen den folgenden Baum.:
Der letzte Schritt ist erreicht, wenn alle Zeichen in den Baum eingefügt sind..
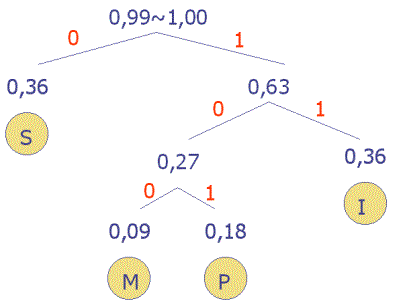
Dieser Baum zeichnet sich dadurch aus, dass in der sog. Wurzel immer die 1, und in einem Knoten immer eine Zahl steht, die die Summe ihrer Konten darunter ist. Die Verbindungslinien von Knoten zu Knoten nennt man die Kanten des Baumes. Nach links - unten weisende Kanten bekommen den Wert 0, die nach rechts - unten weisenden den Wert 1. An den Enden des Baumes, man nennt diese Knoten auch Blätter, stehen dann die Zeichen. So erreicht man den Buchstaben P wenn man dem Pfad 1-0-1 folgt. Wir geben deshalb dem Buchstaben P den Kode Code(P)=101. Der Algorithmus, der den Baum aufbaut ist einfach, denn, wie wir gesehen haben, wird beim Einfügen eines neuen Elementes der Baum nur ergänzt aber nicht umstrukturiert. Ein Blick auf den Baum zeigt auch:
wenn man einen Text mit mehr als zwei Zeichen codieren will, können die
0
und 1
nicht gleichzeitig vergeben werden, sondern nur die
1
oder die 0, da an mindestens einem der beiden Kantenenden der Restbaum
angehängt ist. Diese Tatsache beantwortet die Frage, warum wir für den
Text MISSISSIPPI den
Code(S)=0, Code(I)=1,
Code(P)=01 und Code(M)=10
nicht wählen können, denn sonst könnten wir den Baum und seine Struktur
nicht mehr nützen. Aber darauf wollen wir nicht verzichten, warum, das
zeigt die folgenden Überlegungen: Wie man leicht einsehen kann, dient
der Huffman-Baum nicht nur der Kodierung sondern auch der Dekodierung.
Übersendet man also mittels Huffman-Algorithmus komprimierte Zeichenkette, so muss man
dem Empfänger den Kodierungsbaum mitschicken, damit er die empfange
Zeichenkette wieder decodieren also dekomprimieren kann. In der
Praxis geschieht dies so, dass man in den sog. Header einer komprimierten
Datei den Hufmannbaum schreibt. Das hat natürlich zur Konsequenz, dass das
Komprimieren sich erst dann lohnt, wenn der Speichergewinn nicht durch das
Mitspeichern des Baum wieder verloren geht. Je größer die Datei ist, um so
mehr lohnt die Kompression.
|
|
Zum Demo-Applet ETH-Zürich |
Das
Applet auf der Seite von ETH-Zürich erzeugt zu einer eingegebenen
Zeichenkette den Huffman-Kode. Zusätzlich kann man den Aufbau des
Huffman-Baumes schrittweise verfolgen. |
| zu | 29.3 Übungen |
| zur Startseite | www.pohlig.de (C) 2004 MPohlig |