| 33.4
Häufigkeitsverteilung bei unterschiedlichen Sprachen |
|
|
Download: TextAnalyse.java rauchen.txt bush.txt |
Wir wollen die Häufigkeit der einzelnen Buchstaben in einem Text untersuchen. Wir benutzen dazu das Programm TextAnalyse.java. Wir benutzen dazu die beiden Texte rauchen.txt und bush.txt. Aus den Dateien wurden harte Zeilenumbrüche entfernt. |
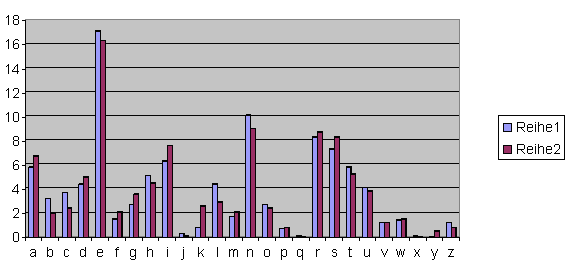
Die Häufigkeit der einzelnen Buchstaben in der Datei rauchen.txt ist:
A: 5.8% B: 3.2%
C: 3.7% D: 4.4%
E: 17.1% F: 1.5% |
|
Die Häufigkeit der einzelnen Buchstaben in der Datei bush.txt ist: |
|
| A: 6.7%
B: 2.0% C: 2.4% D: 5.0%
E: 16.3% F: 2.1% G: 3.6% H: 4.5% I: 7.6% J: 0.1% K: 2.6% L: 2.9% M: 2.1% N: 9.0% O: 2.4% P: 0.8% Q: 0.0% R: 8.7% S: 8.3% T: 5.2% U: 3.8% V: 1.2% W: 1.5% X: 0.0% Y: 0.5% Z: 0.8% In beiden Tabellen sind die drei häufigsten Buchstaben gelb unterlegt, sie sind in beiden Tabellen die gleichen. Der Abstand zwischen den drei Häufigsten ist 9 - 4 (wir beginnen bei dem Buchstaben mit der größten Häufigkeit. U.U. müsste man über 'Z' wieder bei 'A' beginnend weiterzählen.. |
|
 |
|
| Die Häufigkeitsverteilungen der beiden, völlig verschiedenen Texten sind frappierend ähnlich. Weitere Vergleiche mit anderen, willkürlich gewählten, aber hinreichend langen Texten, zeigen das gleiche Bild. | |
| Verwenden
wir einen englischen Text, so zeigt die Buchstabenverteilung eine für die
englische Sprache typische Verteilung.
A: 9.1% B: 1.3% C: 3.0% D: 4.1%
E: 11.3% F:
2.1%
|
|
| zu | 33.5 Entschlüsseln mit Hilfe einer Häufigkeitsverteilung |
| zur Startseite | www.pohlig.de (C) MPohlig 2004 |